Cada consultor o consultora de sostenibilidad con quien hablo tiene el mismo conflicto interno con la IA. La usamos porque funciona. Nos preocupa el coste energético porque nos pagan por preocuparnos por el coste energético. La conversación termina dando vueltas al mismo punto y quienes hemos hecho las paces con usar IA hemos aterrizado más o menos en el mismo compromiso. Cambiar a un modelo de menos razonamiento en tareas rutinarias. Queries más baratas, menos cómputo por query, conciencia tranquila.
Es una media respuesta razonable. Tampoco es la palanca más grande.
Cuando me metí en los datos del Anthropic Economic Index sobre uso de IA en consultoría de sostenibilidad, el patrón que me llamó la atención no fue qué modelo elegía la gente. Fue cuánto cómputo quemamos todos en el mismo contexto repetido, regenerado sesión tras sesión. Voz de marca pegada. Marco metodológico pegado. Background del proyecto pegado. De tres a cinco mil tokens de overhead estructural antes de que alguien llegue a la pregunta de verdad.
La mayor parte de eso se puede evitar. El prompt caching de Anthropic reduce el coste del contexto repetido en un 90%. La metadata de los skills se carga en unos 100 tokens, y el cuerpo completo del skill (unos 5.000 tokens) se carga solo cuando hace falta. Los sub-agentes corren con ventanas de contexto aisladas que evitan el hinchado de una conversación única. Usadas en conjunto, estas funciones son una respuesta más arquitectónica a la misma ansiedad que cambiar de modelo. Una intervención de nivel sistémico que dura más que elegir un modelo más pequeño, y los ahorros resultan ser mayores.
Llevo unos meses reconstruyendo mi flujo de consultoría alrededor de ellas. Cuando compartí uno de estos patrones con una académica estadounidense recientemente, le sorprendió que no se enseñara más. Así que esto es la versión larga de esa conversación. Lo que he encontrado, qué pintan las matemáticas reales y dónde la arquitectura deja de funcionar. La pieza anterior sobre Claude Code para investigación en sostenibilidad sienta el contexto más amplio si aún no la has leído.
Lo más relevante
- Saltarse la generación de imágenes con IA en visuales estructurados. Gráficos en matplotlib, HTML renderizado a imagen y fotos de stock de Unsplash recortan coste y energía de producción de imágenes en ~97% frente a DALL-E o Gemini. El mayor ahorro individual de este análisis.
- El contexto cacheado cuesta el 10% del contexto fresco. El prompt caching de Anthropic ahorra hasta el 90% de tokens de entrada en trabajo sostenido multi-turno.
- La carga progresiva recorta el baseline. La metadata de los skills se carga a ~100 tokens. El cuerpo de 5.000 tokens solo se carga cuando es relevante. Dejas de pagar por skills que no estás usando activamente.
- Los sub-agentes baten a una sola sesión hinchada. Tres agentes enfocados a 5-10K tokens cada uno cuestan menos cómputo que una sesión monstruo a 100K, y producen mejor output.
- Ahorro mensual realista en flujos de texto: alrededor del 50-60%. Más alto en trabajo iterativo sostenido, cerca de cero en tareas one-shot.
Por qué no todas las conversaciones son iguales
Los titulares sobre uso energético de la IA son fáciles de encontrar. La electricidad de los centros de datos va en una trayectoria de 460 TWh en 2022 a aproximadamente 1.050 TWh para 2026. Las emisiones de carbono de la IA podrían alcanzar 32-80 megatoneladas de CO2 en 2025. Se citan tan a menudo que se vuelven ruido.
El número que importa más para un profesional en activo es el de por query. El análisis de Epoch AI en 2026 sitúa la mediana de energía por query de LLM en unos 0,31 Wh, con la mayoría de queries entre 0,16 y 0,60 Wh. Es menor de lo que sugieren los titulares, pero suma. Doce sesiones de 5.000 tokens al mes, replicadas en todo el equipo, es energía real. Multiplica por cada consultora ejecutando cada flujo sin pensar en la economía de tokens y te sale la previsión del centro de datos.
La mayoría de consultores que conozco regenera su contexto cada sesión. Pegando el posicionamiento de la firma, el background del proyecto, las prioridades del financiador, las preferencias metodológicas. Son 3.000 a 5.000 tokens de input repetido en cada llamada, pagados en cómputo y, en última instancia, en energía.
El sistema de skills en Claude Code es una de las respuestas más limpias a ese desperdicio que he visto. No es la única respuesta. Pero es la que encaja con cómo funciona la consultoría en realidad, donde los mismos patrones se repiten en cada cliente y la misma experticia de dominio se codifica una y otra vez.
Carga progresiva: la compresión x50
Los skills funcionan como un catálogo de fichas de biblioteca. Cada skill expone su metadata arriba. Unos 100 tokens que describen qué hace y cuándo usarlo. Claude los escanea en cada sesión como parte de su contexto base. Barato.
El cuerpo completo del skill, típicamente 3.000 a 5.000 tokens de instrucciones detalladas, scripts y archivos de referencia, solo se carga cuando el skill se vuelve relevante para la tarea activa. Un skill de redacción de propuestas se queda en 100 tokens hasta que realmente empiezas a trabajar en una propuesta. Entonces se carga el cuerpo completo. Cuando cambias a una tarea distinta, queda cargado el resto de la sesión y luego desaparece.
El ahorro honesto de la carga progresiva no es enorme por sí solo. Si necesitas el contexto de la propuesta, el cuerpo sigue cargando a 5.000 tokens. El beneficio es estructural: no pagas el coste de contexto de los skills que no estás usando. Con cinco skills cargados como metadata, tu overhead base es 500 tokens, no 25.000. La economía real entra cuando esto se combina con el cacheo, que es el siguiente mecanismo.
He construido este tipo de skill para varios patrones recurrentes en mi propia práctica:
- research-writing-assistant: codifica mi voz de marca, mis directrices de escritura y el pipeline multi-etapa que uso para artículos SEO. Se carga solo cuando realmente estoy escribiendo.
- proposal: conoce mi marco de pricing, mis patrones de propuestas pasadas y los pasos de ensamblaje para una propuesta nueva. Permanece dormido hasta que estoy preparando una.
- gsc-audit: contiene el marco de análisis de siete puntos para auditorías de Google Search Console. Se activa solo cuando estoy auditando un sitio.
- article-images: encapsula los helpers de branding de matplotlib y las plantillas de gráficos para no pedirle a Claude que escriba el mismo código Python desde cero cada vez.
Ninguno de estos skills se carga en su totalidad en una sesión normal. Son baratos de escanear, caros solo cuando se usan. Ese es el punto.
Cacheo: el 90% de descuento sobre contexto repetido
El prompt caching de Anthropic potencia el ahorro. Una vez que un bloque de contexto se ha escrito en caché, las lecturas posteriores cuestan el 10% del precio de entrada estándar. El punto de equilibrio es rápido. El cacheo se amortiza tras una sola relectura en la ventana de 5 minutos, o dos lecturas en la ventana de 1 hora.
Los skills y los archivos CLAUDE.md encajan casi perfectamente con el cacheo. Son estables entre sesiones. Son lo bastante grandes para que valga la pena cachearlos. Se referencian repetidamente. La arquitectura premia exactamente los patrones que Anthropic optimizó en el caché.
En la práctica, el cacheo importa sobre todo en trabajo sostenido multi-turno. Una sesión de redacción de propuesta donde itero sobre el mismo cuerpo de skill durante ocho o diez turnos en una hora se beneficia enormemente. El primer turno escribe la caché a 6.250 tokens efectivos, luego cada turno posterior lee a 500 tokens en lugar de 5.000. Una sesión de diez turnos cuesta unos 10.750 tokens de input estructural en lugar de 50.000. Una reducción del 78% dentro de una sesión sostenida.
A lo largo de un mes entero, el ahorro es menor. Las ventanas de caché expiran. Sesiones en días distintos no comparten caché. Un consultor cuyo mix mensual es pesado en proyectos sostenidos ve más ahorro que alguien haciendo tareas dispersas. La forma más limpia de pensarlo. El cacheo funciona en los patrones a los que dedicas una tarde activa iterando, no en los patrones que tocas una vez cada quince días.
El hallazgo del “lo construí una vez en lugar de cuarenta y siete veces”
Este es el ahorro que más me sorprendió. Antes de construir skills como dios manda, le pedía a Claude que escribiera el mismo script de gráficos en Python cada vez que necesitaba un plot para un artículo. Le pedía que ensamblara la misma estructura de propuesta cada vez que preparaba una. Pegaba las mismas instrucciones de voz de marca cada vez que redactaba un post de LinkedIn.
Cada sesión individual parecía estar bien. El agregado era desperdicio.
El skill article-images es el ejemplo más limpio. Antes de que existiera el skill, cada artículo con gráficos tenía su propio script Python único. Cada script nuevo le pedía a Claude que generara unas 200 líneas de boilerplate de matplotlib, mapeo de colores de marca, atribución de fuentes y lógica de marca de agua. Quizá 8.000 a 12.000 tokens de output por script. A lo largo de un año de artículos, cientos de miles de tokens regenerados.
El skill consolida eso en una plantilla que copio y edito. El módulo compartido branding.py gestiona los colores de marca y el pie. Los nuevos gráficos cuestan unos pocos cientos de tokens de ediciones, no 10.000 de regeneración.
El patrón: cualquier código o contenido que le hayas pedido a Claude que produzca más de tres veces es candidato a skill. No porque Claude no pueda hacerlo de nuevo. Porque pedirle a Claude que lo haga de nuevo es pagar dos veces por la misma respuesta. Una vez existe el skill, pagas por las diferencias, no por el boilerplate.
Aquí también tengo que ser honesto sobre que el ahorro de tiempo es la historia más grande. Los 8.000 tokens de código de gráfico regenerado cuestan quizá 4 céntimos en la API de Anthropic. No es para mover una estrategia. Pero los 20 minutos que dedico a revisar y ajustar frente a regenerarlo todo entero, ahí está el compounding real.
La trampa de la generación de imágenes
El ejemplo más limpio de este patrón, y el que una académica estadounidense me dijo recientemente que le sorprendía no encontrar más extendido, es la creación de imágenes.
El flujo por defecto al que recurre la mayoría es pedirle a un modelo de IA de imágenes. Generar un gráfico. Generar una imagen destacada. Generar una stat card. DALL-E 3 cobra entre 0,04 y 0,12 dólares por imagen. El Imagen 4 Fast de Gemini sale a 0,02 dólares, pero el Gemini 3 Pro Image de mayor calidad va a 0,134 dólares por renderizado estándar y a 0,24 a 4K. La opción barata sigue costando unas 50 veces más que ejecutar matplotlib en tu portátil.
La energía amplía la brecha. Un paper de 2026, “The Hidden Cost of an Image”, midió 17 modelos de generación de imágenes y encontró aproximadamente 2,9 Wh por imagen de media. Stable Diffusion 3 Medium a 1024×1024 quema unos 2.282 julios de cómputo total por imagen. Los modelos de mayor calidad pueden llegar a 4.400 julios. A lo largo del año, el reportaje previo de MIT Technology Review encontró que generar una imagen usa aproximadamente la energía de cargar un teléfono.
Compara ahora tres alternativas programáticas:
- Gráficos de matplotlib: Renderizan localmente en tu portátil. Los cuatro gráficos del artículo que estás leyendo los produjo un script de Python que corrió en unos tres segundos en total. Coste cloud: cero. Energía: unos pocos milijulios de tiempo de CPU, muy por debajo de 0,01 Wh.
- HTML renderizado a imagen: Para stat cards, posts sociales o tarjetas de título con marca, escribes una plantilla HTML con CSS que usa las variables de marca de tu sitio y luego renderizas a PNG con un navegador headless o weasyprint. Mismo cómputo casi cero, totalmente reproducible, las ediciones llevan segundos.
- API de Unsplash: Para fotografía de stock, la API de Unsplash devuelve una URL a una foto existente. Sin generación, sin renderizado, solo una consulta a base de datos. Gratis para uso no comercial. La energía es lo que cuesta servir una sola respuesta HTTP.
Intenté poner números aproximados a un mes típico con muchas imágenes. Un consultor que publica tres o cuatro artículos al mes, cada uno con dos gráficos, una imagen destacada y un par de visuales de apoyo, aterriza en 16 a 20 imágenes. Con generación por IA:
- 16 imágenes a 0,04-0,13 dólares cada una = 0,64 a 2,08 dólares en gasto de API
- Multiplicado por las 3-5 iteraciones que la mayoría de la gente necesita para acertar con la imagen correcta: 2 a 10 dólares por mes
- Energía: 16 imágenes × 2,9 Wh × 4 iteraciones de media ≈ 185 Wh por mes
Con matplotlib, plantillas HTML y Unsplash:
- Gasto de API en gráficos y fotos de stock: 0 dólares
- Llamada ocasional a Gemini para una edición fotográfica genuina (cambio de cara, añadir objeto): una o dos al mes a 0,04 dólares = 0,04-0,08 dólares
- Energía: menos de 5 Wh por mes, casi todo en cómputo local
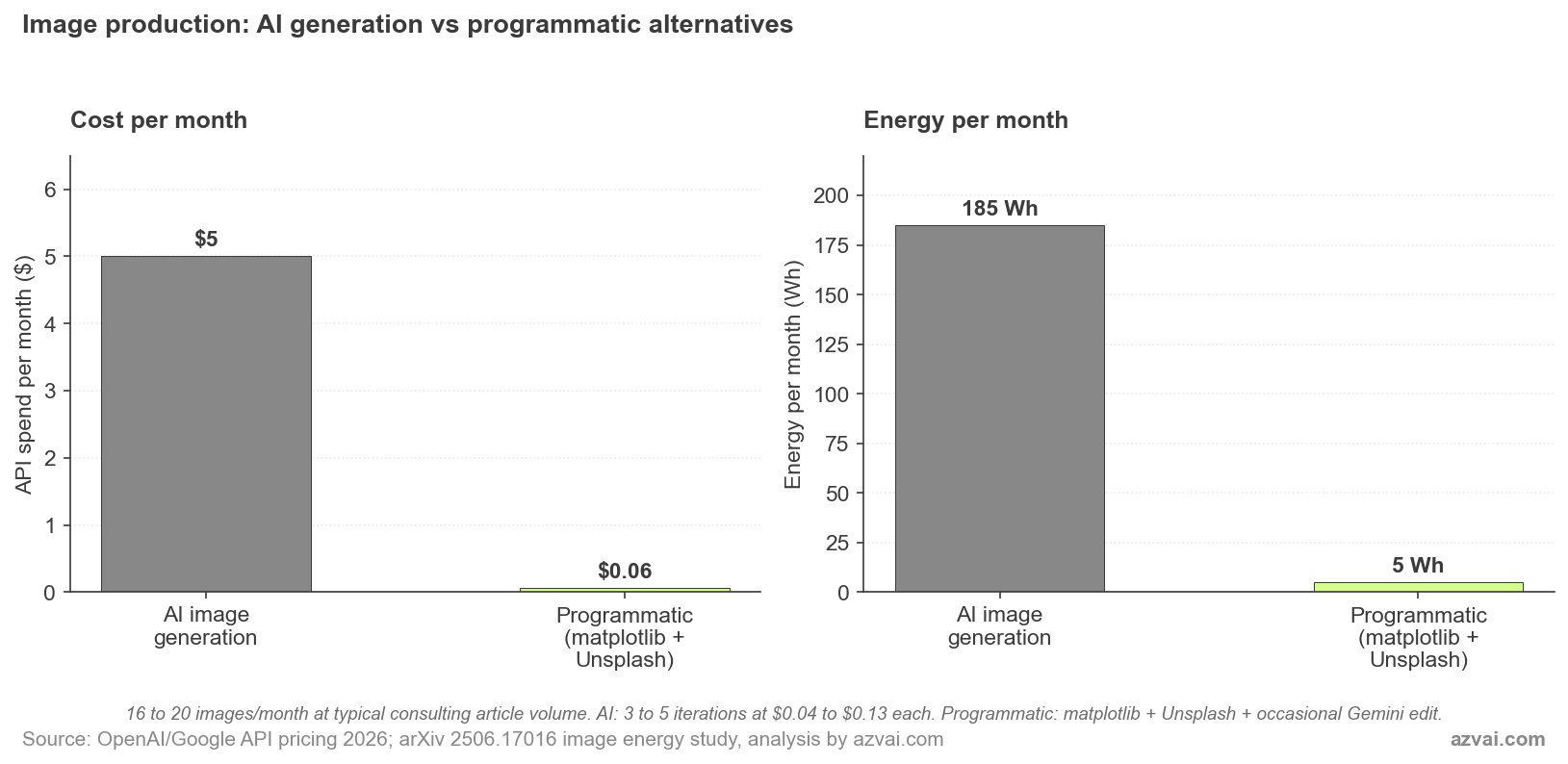
Aproximadamente un 97% de reducción tanto en gasto de API como en energía para la parte de producción de imágenes del flujo. Proporcionalmente, este es el mayor ahorro de cualquier parte de la arquitectura que he descrito. También es el más contraintuitivo, porque la mayoría de la gente opta por la generación con IA sin haberse preguntado si la tarea realmente lo necesita.
La regla que uso: si la imagen es estructurada (gráficos, stat cards, texto con marca), genérala programáticamente. Si es fotográfica y única, busca en Unsplash primero. Solo recurre a generación con IA cuando el resultado tenga que ser a la vez fotográfico y específico para tu proyecto. Esa última categoría es genuinamente pequeña. La mayor parte del trabajo de imagen en escritura de consultoría cae en las dos primeras.
Este es también un caso enseñable para estudiantes de sostenibilidad. El argumento de que “los modelos de imagen con IA reducirán el coste de carbono de la fotografía de stock” suena plausible hasta que lo comparas contra una biblioteca de fotos existente. Unsplash ya tiene la foto. Generar una nueva para la misma necesidad es puro cómputo adicional. La misma lógica aplica al stack más amplio de aplicaciones de IA en economía circular. Reutilizar recursos existentes casi siempre bate a generar nuevos.
Aislamiento de contexto con sub-agentes
La otra elección arquitectónica que ahorra cómputo de forma silenciosa es la delegación a sub-agentes. Una sola conversación que corre durante 40 turnos degrada en calidad después de unos 20. Cualquiera que haya usado Claude en una tarea larga lo ha sentido. El modelo pierde el hilo, repite sugerencias previas o contradice decisiones de antes en la sesión.
El instinto es resetear y empezar de nuevo. Pero empezar de nuevo significa volver a pegar el contexto. Tokens repetidos. Energía repetida.
La aproximación más limpia es romper el trabajo en etapas, cada una corriendo como un sub-agente con contexto aislado. Mi skill research-writing-assistant lo hace explícitamente. La etapa 1 (investigación) corre en su propio contexto. La etapa 2 (planificación de outline) recibe solo los hallazgos de investigación, no la conversación cruda. La etapa 3 (redacción) recibe el outline, no las notas de investigación. Cada etapa se mantiene cómodamente por debajo de 20 turnos. Cada etapa corre en 5.000 a 15.000 tokens de contexto enfocado.
Compara eso con correr todo en una sola sesión. El pipeline completo quemaría más de 100.000 tokens de contexto, mucho de él redundante, con caída de calidad en la segunda mitad. La versión con sub-agentes usa menos cómputo y produce mejor output. Las dos victorias vienen de la misma elección arquitectónica.
La misma lógica aparece en mi skill de propuestas (sub-agentes separados para investigación de cliente, definición de alcance y ensamblaje de pricing), y en el skill de auditoría que estoy esbozando ahora para reconciliaciones de subvenciones IFO/AFO (agentes separados para extracción de facturas, cruce con baseline y reporte de gaps). El patrón se transfiere limpiamente.
Un mes típico de consultoría, con y sin
Intenté poner números aproximados a la diferencia en mi propia práctica. Las cifras de abajo son ilustrativas, no auditadas, pero están aterrizadas en el tipo de trabajo que de verdad hago.
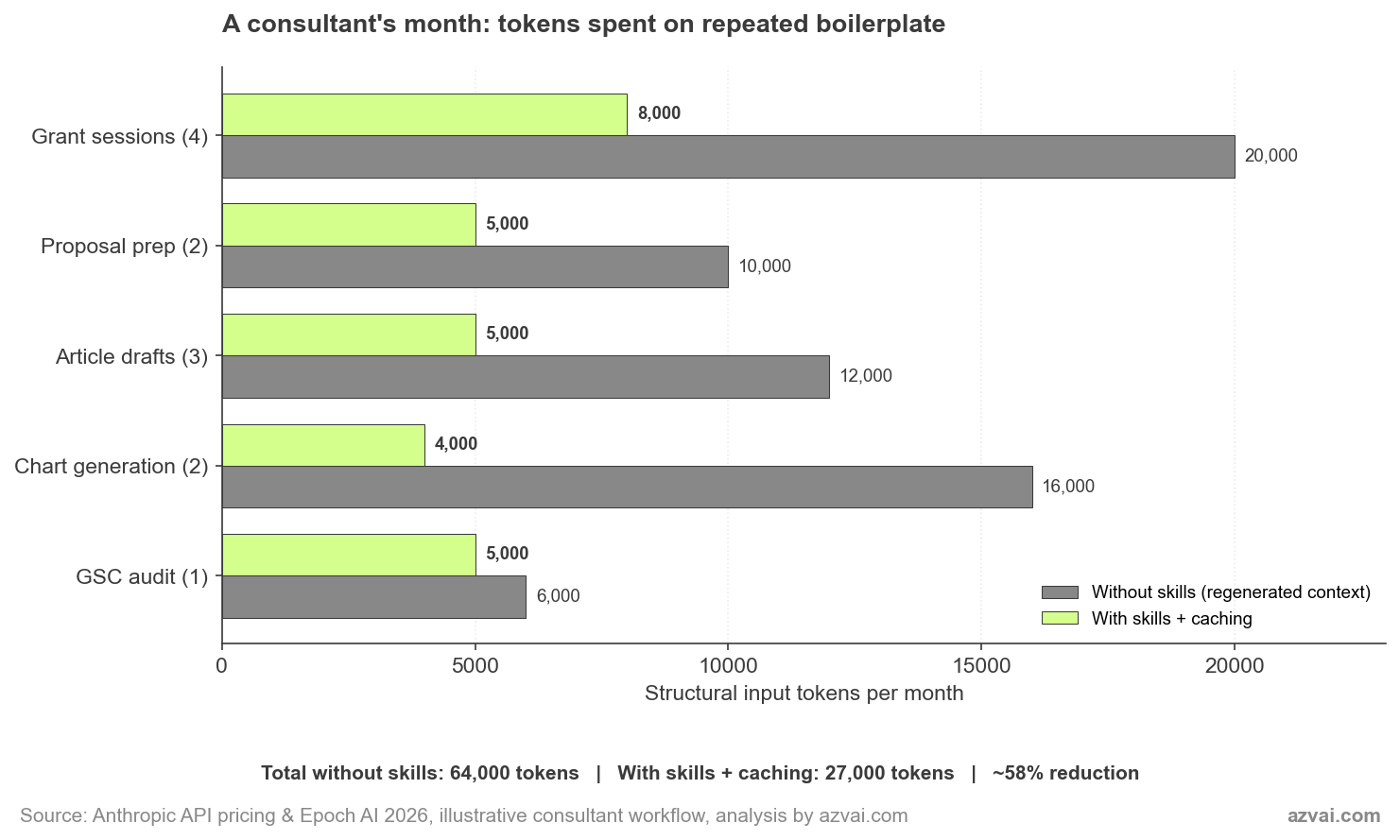
El titular del 58% esconde de dónde vienen realmente los ahorros. El cacheo hace el trabajo pesado en el trabajo sostenido multi-turno, como la redacción de propuestas donde iteras sobre el mismo cuerpo de skill durante 8 a 10 turnos en una hora. El código de skill reutilizable (el skill article-images reemplazando el Python de gráficos regenerado) entrega el mayor ahorro individual por tarea, alrededor del 75%. Las tareas one-shot como una auditoría GSC apenas se mueven porque no hay nada que cachear.
La forma honesta de plantearlo. La arquitectura de skills no es un descuento uniforme del 58% en cada sesión. Es un descuento brusco en los patrones que se repiten, un descuento modesto en patrones que no se repiten y casi nada en trabajo genuinamente puntual. Un consultor cuyo mix mensual es pesado en proyectos sostenidos ve más ahorro que alguien haciendo tareas dispersas.
A 0,31 Wh de mediana por query de Epoch, la energía absoluta involucrada es pequeña. El salto de 27.000 a 64.000 tokens representa quizá 10-20 Wh de cómputo a lo largo del mes. No es la clase de número que cierra una central. Pero es la clase de número que sugiere que la pregunta correcta no es si usar IA. Es si tu arquitectura de uso está desperdiciando cómputo de la forma en que lo hacen la mayoría de los setups actuales.
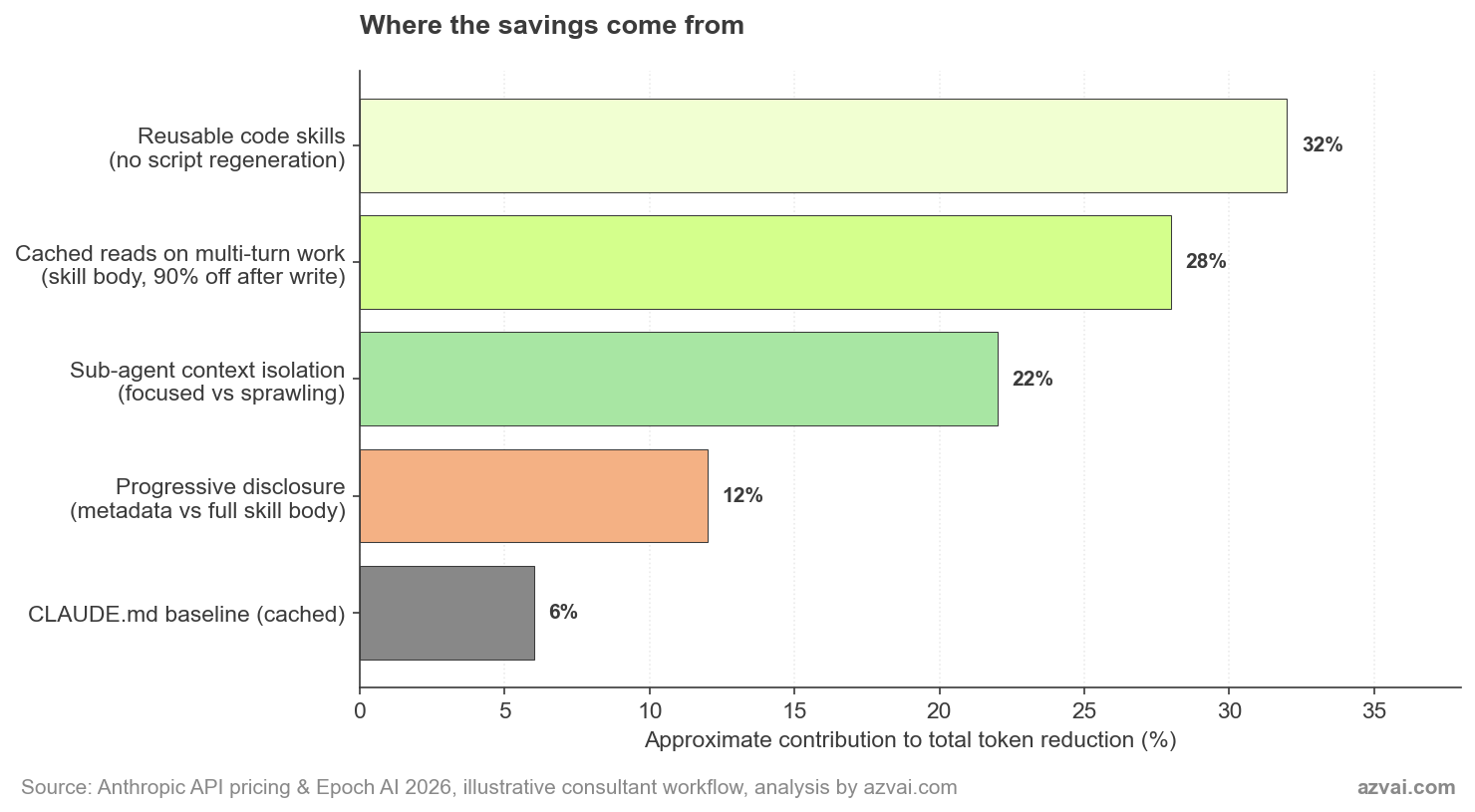
El desglose de arriba muestra por qué ningún mecanismo único es la respuesta. El código reutilizable en skills es el mayor contribuyente en mi flujo porque genero muchos gráficos. Para alguien cuyo trabajo es más conversacional, el cacheo en borradores multi-turno lideraría. La arquitectura compone, que es la razón por la que merece la pena pensarlo.
Estos patrones se enseñan. Si quieres implantarlos en tu equipo en lugar de descubrirlos por ensayo y error, forman parte del temario de nuestra formación en IA generativa para empresas.
Dónde deja de funcionar esto
Debería ser directo con los límites. Los skills no son la respuesta para todo, y el marco energético tiene sus propias salvedades honestas.
- El trabajo exploratorio one-shot no se beneficia. Si estás investigando un tema que no volverás a tocar, construir un skill cuesta más de lo que ahorra. Los skills se amortizan en patrones recurrentes.
- Crear un skill tiene coste inicial. Construir un skill research-writing-assistant limpio me llevó varias iteraciones y miles de tokens. Amortizado en muchos usos, vale la pena. En un solo uso, no.
- El cacheo solo ayuda dentro de la ventana de caché. Las ventanas de 5 minutos y 1 hora significan que el cacheo es más valioso para sesiones de trabajo activas, no para revisiones esporádicas separadas por días.
- La reducción de tokens no es lineal con la energía. La relación entre tokens de API y julios de cómputo es aproximada. Las lecturas cacheadas siguen consumiendo algo de cómputo de inferencia. Los ahorros son reales pero más sucios de lo que sugieren las cifras de coste.
- La mayor parte del cómputo pasa en otra parte. Entrenar un modelo frontera empequeñece cualquier ahorro de inferencia de un usuario individual. Si queremos mover la curva del centro de datos, las palancas de política están en la capa de modelos e infraestructura, no en el flujo del consultor. Profundicé en esa lectura a nivel de empresa e infraestructura en la foto de Anthropic en divulgación ambiental.
Ese último punto es el que me hace cauto con sobrevender. Las ganancias energéticas de la arquitectura de skills son reales al margen y son acumulativas entre usuarios. Pero la historia más grande sigue siendo el tiempo que recuperas. La eficiencia energética y de cómputo es un efecto secundario feliz de una arquitectura elegida principalmente por calidad de output y tiempo del consultor. Prefiero ser honesto con eso que pretender que mi setup de skills está haciendo trabajo climático que no está haciendo.
Lo que sí hace es alinear dos cosas que a menudo tiran en sentido opuesto. Trabajar mejor y usar menos. Esa alineación es más rara de lo que debería ser en este espacio.
Preguntas frecuentes
¿Son los ahorros realmente significativos, o esto es solo cómo se presenta?
Las dos cosas. Los ahorros de tokens (alrededor del 78% sobre input estructural base en mi flujo) son reales y se traducen en ahorros de cómputo y energía aproximadamente proporcionales. Pero la energía absoluta involucrada es pequeña. El caso honesto a favor de los skills es que ahorran tiempo de consultor y producen mejor output. La eficiencia energética es una victoria genuina pero secundaria.
¿Funcionan los skills para consultores no técnicos?
Sí. El skill research-writing-assistant en mi carpeta es mayormente markdown, no código. El skill de propuestas es un proceso de ensamblaje documentado. No necesitas escribir Python para construir un skill. Necesitas poder describir un flujo recurrente con la claridad suficiente para que Claude pueda seguirlo.
¿Cómo sé si algo es candidato a skill?
Si le has pedido a Claude el mismo tipo de output más de tres veces, es un candidato. Si tu contexto pegado es el mismo en cada sesión relacionada, ese contexto pertenece a un skill o a un archivo CLAUDE.md. El disparador es la repetición, no la complejidad.
¿Cuál es la relación entre skills y prompt caching?
Los skills funcionan mejor con cacheo, pero son funciones independientes. El cacheo es una función de facturación e infraestructura que reduce el coste sobre contexto repetido. Los skills son un patrón de arquitectura de contexto que organiza y entrega el contexto correcto en el momento correcto. Juntos, recortan tanto cómputo como complejidad. Por separado, cada uno sigue ayudando.
¿Dónde puedo ver tus skills reales?
Los cinco skills detrás de este artículo están ahora públicos en el hub de skills de Claude Code con readmes en lenguaje llano y bundles descargables. Open source, gratis, con licencia MIT. Si quieres aviso cuando llegue un skill nuevo, escríbeme y te apunto a la lista corta.